Balıkçıl'ın Koku Duyusu: Kelimeler Matematiğe Nasıl Dönüşür?

Serinin bir önceki yazısında, Balıkçıl Kuşu'muzun 'usta' bir alet kullanıcısı olduğunu görmüş, devasa 'bilgi balıklarını' nasıl sindirilebilir lokmalara ayırdığını (chunking) öğrenmiştik. Artık elimizde özenle hazırlanmış porsiyonlarımız olduğuna göre, her bir lokmaya, sadece Balıkçıl'ın anlayabildiği eşsiz ve görünmez diyebileceğim 'anlam kokusunu' işleme zamanı. Bu, nehir kenarında sessizce, sürekli ve doğal olarak gerçekleşen, bir hokkabazlıktır.
Balıkçıl'ın Zihnindeki Koku Haritası: Yakınlık ve Yönler
Balıkçıl Kuşu'nun beyni, kokuları sadece bir liste olarak tutmaz. Onun zihninde, birbiriyle ilişkili kokuların birbirine yakın olduğu, zıt kokuların ise uzaklaştığı çok boyutlu bir harita vardır. Bu haritada "Kral"ın kokusu ile "Kraliçe"nin kokusu arasındaki ilişki, "Erkek" ile "Kadın" kokuları arasındaki ilişkiye çok benzer. Balıkçıl, bu ilişkileri içgüdüsel olarak bilir ve haritasında yönünü buna göre bulur.
Bu içgüdüsel yetenek kulağa sihir gibi geliyor, değil mi? Aslında bu sihrin arkasında, Vektör Uzayı dediğimiz kafa yakan bir matematik yatıyor. Gelin, Balıkçıl'ın beynindeki bu haritayı bir anlığına bizim dünyamıza, matematiğin diline çevirelim.
Teknik olarak "embedding", bir metin parçasını, yüzlerce, hatta binlerce sayıdan oluşan bir listeye, yani bir vektöre dönüştürme işlemidir. Bu vektör, o metnin çok boyutlu bir haritadaki (Vektör Uzayı) koordinatıdır. Bu haritanın bizim bildiğimiz gibi üç boyutu (x, y, z) yoktur; bir embedding modelinin 768 veya daha fazla boyutu olabilir. Her bir boyut, modelin metinleri analiz ederek öğrendiği "asalet", "cinsiyet", "eylem", "zaman" gibi soyut bir anlamsal özelliği temsil eder. Buradaki 'asalet' veya 'cinsiyet' benzetmeleri, işi anlaşılır kılmak için yaptığımız bir basitleştirmedir. Gerçekte, bu boyutların çoğu insanlar için anlaşılmaz ve yorumlanması zordur. Model, bu soyut kavramları yüzlerce boyuta yayılmış karmaşık bir desenler kombinasyonu olarak öğrenir. Yani, 247. boyut tek başına "cinsiyet"i temsil etmez. Daha ziyade, "cinsiyet" gibi bir kavram, onlarca farklı boyutun ağırlıklarının birleşimiyle oluşan bir desendir. Modelin zihni, bizimkine benzemez; o, anlamı istatistiksel bir mozaik olarak görür. Bu harita öyle akıllıca tasarlanmıştır ki, anlamsal ilişkiler matematiksel işlemlere dönüşür. Bir noktadan başlayıp, belirli bir yönde ve mesafede ilerlediğinizde, anlamlı başka bir noktaya ulaşırsınız:
Vektör('Kral') - Vektör('Erkek') + Vektör('Kadın') ≈ Vektör('Kraliçe')
Bu denklem, kelimelerin artık sadece harf yığınları olmadığını, aralarında ölçülebilir, geometrik ilişkiler olan matematiksel nesnelere dönüştüğünü gösterir.
Peki, Balıkçıl iki kokunun "benzer" olduğuna nasıl karar verir? Onların haritadaki "mesafesini" mi ölçer? Hayır, daha zekice bir şey yapar: Yönlerini kontrol eder. Karanlık bir odada iki el feneri düşünün. Fenerler duvarda birbirine çok yakın noktaları aydınlatıyorsa, yönlerinin benzer olduğunu söyleriz. Biri duvara daha yakın olsa bile (vektörün büyüklüğü farklı olsa bile), eğer aynı noktayı hedefliyorlarsa (yönleri aynıysa), aralarındaki benzerlik yüksektir. Balıkçıl'ın bu 'yön' odaklı avlanma tekniğinin mühendislikteki yansıması, Kosinüs Benzerliği ile ifade edilir. Peki, neden Öklid Mesafesi gibi basit bir uzaklık ölçümü değil de Kosinüs Benzerliği? Balıkçıl cevaplıyor: "Çünkü bir bilgi parçası çok uzun veya kısa yazılmış olabilir (mesafe büyük olabilir), ama eğer anlamı aynıysa, zihnimdeki haritada aynı yönü gösterecektir." Kosinüs Benzerliği, bu uzunluk farkından etkilenmez ve sadece anlamsal yönün benzerliğine odaklanır. Bu da onu metinler için oldukça etkili bir ölçüt yapar.
Teknik olarak Kosinüs Benzerliği, iki vektör arasındaki açının kosinüsünü ölçerek -1 (tam zıt) ile +1 (tam aynı) arasında bir skor üretir. Bu yöntem, milyonlarca vektör arasında en benzer olanları bulmak için hesaplama açısından son derece verimli olduğu için yaygın olarak benimsenen bir yaklaşım haline gelmiştir.
Peki, tüm bu anlattıklarımızı soyut birer fikir olmaktan çıkarıp, somut bir testle ispatlayamaz mıyız? Elbette edebiliriz. Tek ihtiyacımız olan birazcık python bilmek. Anlattıklarımızı test etmek için aşağıda göreceğiniz basit bir python betiği hazırladık.
import numpy as np
import matplotlib.pyplot as plt
# --- Fonksiyonlarımızı Tanımlayalım ---
def cosine_similarity(vec1, vec2):
"""İki vektör arasındaki kosinüs benzerliğini hesaplar."""
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
if norm_vec1 == 0 or norm_vec2 == 0:
return 0
return dot_product / (norm_vec1 * norm_vec2)
# --- Temsili Vektörlerimizi Oluşturalım ---
# Gerçekte bu vektörler yüzlerce boyuta sahip olur.
# Buradaki amaç, sadece yönlerini göstermektir.
# "Yapay zeka" ve "Makine öğrenmesi" benzer yönlere sahip olmalı
yapay_zeka = np.array([0.8, 0.6])
makine_ogrenmesi = np.array([0.7, 0.5])
# "Lahana yemeği" ise tamamen farklı bir yöne sahip olmalı
lahana_yemegi = np.array([-0.5, 0.8])
# --- Benzerlikleri Hesaplayalım ve Sonuçları Görelim ---
# 1. Anlamsal olarak yakın iki kavramı karşılaştıralım
sim_ai_ml = cosine_similarity(yapay_zeka, makine_ogrenmesi)
# 2. Anlamsal olarak uzak iki kavramı karşılaştıralım
sim_ai_cabbage = cosine_similarity(yapay_zeka, lahana_yemegi)
print("--- Anlamsal Benzerlik Sonuçları ---")
print(f"'Yapay Zeka' ve 'Makine Öğrenmesi' Benzerlik Skoru: {sim_ai_ml:.4f}")
print(f"'Yapay Zeka' ve 'Lahana Yemeği' Benzerlik Skoru: {sim_ai_cabbage:.4f}")
print("\n--- Yorum ---")
print("Gördüğünüz gibi, anlamsal olarak yakın kavramların skoru +1'e çok yakınken,")
print("alakasız kavramların skoru 0'a çok daha yakındır.")
# --- Görselleştirme ---
plt.figure(figsize=(8, 6))
# Vektörleri çiz ve isimlendir
plt.quiver(0, 0, yapay_zeka[0], yapay_zeka[1], angles='xy', scale_units='xy', scale=1, color='r', label='Yapay Zeka')
plt.quiver(0, 0, makine_ogrenmesi[0], makine_ogrenmesi[1], angles='xy', scale_units='xy', scale=1, color='b', label='Makine Öğrenmesi')
plt.quiver(0, 0, lahana_yemegi[0], lahana_yemegi[1], angles='xy', scale_units='xy', scale=1, color='g', label='Lahana Yemeği')
# Grafik ayarları
plt.xlim(-1, 1)
plt.ylim(-1, 1)
plt.axhline(y=0, color='k', linestyle='-', alpha=0.2)
plt.axvline(x=0, color='k', linestyle='-', alpha=0.2)
plt.grid(True, alpha=0.3)
plt.legend()
plt.title("Vektörlerin 2B Uzayda Yönleri ve Kosinüs Benzerliği")
plt.show()Betiği çalıştırdığımızda aşağıdaki sonuca ve görsele ulaşacağız:
--- Anlamsal Benzerlik Sonuçları ---
'Yapay Zeka' ve 'Makine Öğrenmesi' Benzerlik Skoru: 0.9997
'Yapay Zeka' ve 'Lahana Yemeği' Benzerlik Skoru: 0.0848
--- Yorum ---
Gördüğünüz gibi, anlamsal olarak yakın kavramların skoru +1'e çok yakınken,
alakasız kavramların skoru 0'a çok daha yakındır.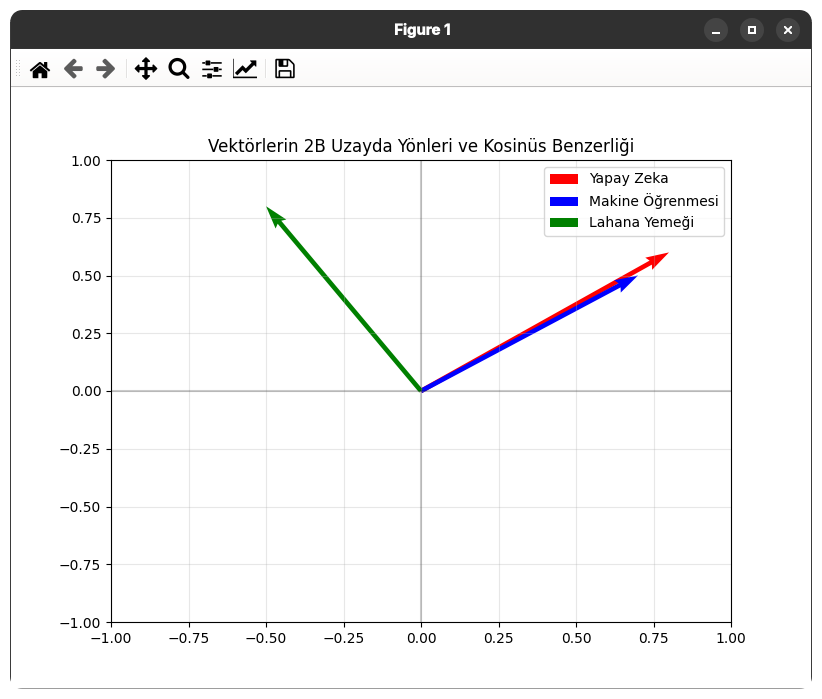
Balıkçıl'ın İki Zekâsı: Avcı İçgüdüsü ve Bilge Anlatıcı
Balıkçıl Kuşu'nun doğasında iki farklı zekâ bir aradadır. Birincisi, son derece hızlı olan 'Avcı İçgüdüsü'dür. Bu zekâ konuşmaz, düşünmez; sadece tek bir işi mükemmel derece yapmak için evrimleşmiştir: Hedef kokuyu anında tanır ve yerini tespit eder. İkincisi ise daha sakin ve derin olan 'Bilge Anlatıcı' zekâsıdır. Bu zekâ, Avcı'nın yakaladığı balığı alır, onu nehirdeki diğer canlılarla, mevsimlerle ve kendi bilgeliğiyle birleştirerek bir hikâye anlatır. Balıkçıl'ın bu iki farklı zekâsının kökeni, evrimsel süreçte karşılaştıkları farklı "hayatta kalma problemlerine" dayanır. Biri "tanımlama", diğeri "yaratma" üzerine uzmanlaşmıştır. Bu, teknoloji dünyamızdaki eğitim hedeflerinin birebir yansımasıdır: Embedding Modelleri (Avcı) ve Büyük Dil Modelleri (Anlatıcı).
Embedding Modelleri (Avcı), "zıtlık tabanlı öğrenme" (contrastive learning) gibi yöntemlerle eğitilir. Peki bu nasıl olur? Balıkçıl'ın avcı içgüdüsü, onu sürekli bir sınavdan geçiren doğa tarafından şekillendirilir. Eğitmen, ona üçlü gruplar halinde kokular sunar: Bir 'çapa' kokusu (örneğin, "yapay zeka"), bir 'olumlu' örnek kokusu ("makine öğrenmesi") ve bir 'olumsuz' örnek kokusu ("lahana yemeği"). Balıkçıl'ın görevi, olumlu örneğin kokusunu çapa kokusuna mümkün olduğunca yaklaştırmak, olumsuz örneğin kokusunu ise mümkün olduğunca uzaklaştırmaktır. Milyonlarca üçlü denemenin sonunda, Balıkçıl'ın beyni (yani modelimiz), en ince anlamsal ayrımları bile yapabilecek şekilde kendini yeniden düzenler. Artık "yapay zeka" ile "makine öğrenmesi"nin kokularını birbirine yakın, "yapay zeka" ile "lahana yemeği"nin kokularını ise birbirine uzak konumlandırmayı öğrenmiştir. İşte bu sürece 'zıtlık tabanlı öğrenme' diyoruz. Bu eğitimde modele, birbiriyle alakalı metin çiftleri verilir ve bu çiftlerin vektörlerini haritada birbirine yaklaştırması istenir. Alakasız metinlerin vektörlerini ise birbirinden uzağa itmesi öğretilir. Tıpkı bir avcının, avının kokusunu diğer tüm kokulardan ayırt etmeyi öğrenmesi gibi, bu modellerin temel amacı da iyi bir "anlam radarı" olmaktır.
Büyük Dil Modelleri (Anlatıcı) ise, "bir sonraki kelimeyi tahmin etme" (next-token prediction) göreviyle eğitilir. Milyarlarca sayfa metni okuyarak tek bir şeyi öğrenirler: "Bu cümledeki kelimelerden sonra, dilbilgisi ve bağlama en uygun bir sonraki kelime hangisidir?" Onların uzmanlığı, olasılıklara dayalı, akıcı bir hikâye anlatmaktır. Bu yüzden biri "anlamın ne olduğunu" söylerken, diğeri "bu anlamla ne anlatılabileceğini" kurgular.
Her Av İçin Doğru İçgüdü: Doğru Embedding Modelini Seçme Sanatı
Usta bir avcı olan Balıkçıl, her ava aynı içgüdüyle yaklaşmaz. Sığ bir deredeki küçük ve çevik bir balığı avlamak için gereken refleksler, derin bir göldeki büyük ve yavaş bir balığı avlamak için gerekenlerden farklıdır. Balıkçıl, avının türüne ve avlandığı sahaya göre içindeki doğru içgüdüyü seçer. Balıkçıl'ın bu adaptasyon yeteneği, bizim için kilit adımlardan birine karşılık geliyor: Yüzlerce farklı embedding modeli arasından kendi 'av sahamıza' (verimize) ve 'avımıza' (amacımıza) en uygun olanı seçmek. Gelin, Balıkçıl'ın karar defterini açalım ve hangi durumda hangi içgüdüyü kullandığına bakalım.
- Avın Büyüklüğü (Asimetrik vs. Simetrik Modeller)
Küçük, çevik bir yem (kısa bir sorgu) ile devasa, yavaş bir balığı (uzun bir doküman) avlamak, iki küçük balığın dansından çok farklı bir tekniktir. RAG sistemleri için genellikle, bu iki farklı yapıdaki metni aynı anlam uzayında etkili bir şekilde karşılaştırmak üzere özel olarak eğitilmiş asimetrik modellere ihtiyaç duyarız. Simetrik modeller ise, iki benzer sorunun ne kadar örtüştüğünü bulmak gibi görevlerde daha başarılıdır.
Peki, bu teknik ayrım pratikte ne anlama geliyor? Şöyle düşünelim: Simetrik bir model, iki metni aynı türden şeylermiş gibi karşılaştırmak için idealdir. Örneğin, "Yapay zeka nedir?" ve "AI nasıl tanımlanır?" gibi iki soru cümlesinin ne kadar benzer olduğunu anlamaya çalışır. Oysa RAG'de yaptığımız şey, genellikle kısa bir soru (sorgu) ile uzun bir cevap (doküman) arasındaki anlamsal uyumu bulmaktır. İşte bu, bir elmayla bir portakalı karşılaştırmak gibidir. Asimetrik bir model, tam olarak bu iş için eğitilmiştir; kısa bir sorgunun vektörünü, uzun bir dokümanın vektörüyle anlamlı bir şekilde karşılaştırabilir ve ne kadar örtüştüklerini doğru şekilde ölçebilir. - Av Sahasının Lideri (MTEB Benchmark)
Balıkçıl, avlanmaya başlamadan önce nehirdeki diğer başarılı kuşları izler. Kimin en büyük balığı yakaladığına (Retrieval), kimin en alakasız yosunları getirdiğine (Precision) ve kimin balık sürüsündeki hiçbir balığı kaçırmadığına (Recall) bakar. Bizim bu gözlem yerimiz, MTEB (Massive Text Embedding Benchmark) gibi lider tablolarıdır. Merak edenler, Hugging Face'in halka açık 'Massive Text Embedding Benchmark (MTEB) Leaderboard' sayfasını ziyaret ederek modelleri 'Retrieval', 'Clustering', 'Classification' gibi onlarca farklı görevdeki performanslarına göre karşılaştırabilir. - Enerji Tasarrufu (Performans vs. Maliyet)
En güçlü dalış, en çok enerjiyi harcar ve Balıkçıl'ı yorar. Bazen daha az enerjiyle %95 isabet oranı, çok fazla enerjiyle %98 isabet oranından daha iyidir. OpenAI'ın text-embedding-3-large modeli 3072 boyutlu dev vektörler üretirken, all-MiniLM-L6-v2 384 boyutlu vektörler üretir. Peki, daha fazla boyut her zaman daha iyi midir? Hayır. Daha fazla boyut, modelin anlamları daha ince detaylarla ayırt edebileceği daha geniş bir 'tuval' sunar. Ancak bu tuvali doğru renklerle ve desenlerle dolduramazsanız, devasa bir tuval sadece karmaşık bir karalama defterine dönüşür. Önemli olan boyutun büyüklüğünden ziyade, o boyutların ne kadar verimli ve anlamlı bilgiyle doldurulduğudur. 384 boyutlu, ancak mükemmel eğitilmiş bir model, 3072 boyutlu vasat bir modeli birçok görevde geçebilir. Bu, depolama maliyetinde ve arama hızında 8 katlık bir fark demektir. Projenizin bütçesi ve anlık yanıt hızı (latency) gereksinimleri, bu seçimi doğrudan etkiler. - Özel Avlar (İnce Ayar / Fine-tuning)
Genel avlanma içgüdüleri her nehirde işe yarar. Ancak zehirli bir yılan balığının yaşadığı özel bir kovukta avlanmak için Balıkçıl, o yılan balığının hareketlerini ve kokusunu öğrenerek içgüdülerini ince ayar (fine-tuning) ile güncellemelidir. Bu, deneyimle kazanılan bir uzmanlıktır. İnce ayar, önceden eğitilmiş genel bir modeli alıp, kendi özel veri setinizle (örneğin 10,000 tıbbi makale) ek bir eğitime tabi tutmaktır. Bu işlem, modelin vektör uzayını, sizin alanınızdaki kavramların inceliklerini daha iyi temsil edecek şekilde "eğip büker".
Balıkçıl'ın Gelecek Vizyonu: Tek Bir İçgüdü Yeterli mi?
Şu ana kadar Balıkçıl'ın, her av için en doğru "tek bir içgüdüyü" nasıl seçtiğini konuştuk. Ancak gelecekteki RAG sistemlerinin tek bir her işi yapan model yerine, daha modüler ve spesifik alanlar üzerinde uzmanlaşmış modeller kullanacağını düşünüyorum.
Sonuç
Gördüğümüz gibi, doğru "anlam kokusunu" seçmek, sadece bir kelimeyi bir sayıya çevirmekten çok daha fazlası; projenizin karakterini, hızını ve zekasını belirleyen stratejik bir karardır. Artık doğal hokkabazlık tamamlandı. Özenle ayırdığımız her bir bilgi balığı lokması, artık Balıkçıl'ın zihnindeki haritada bir yeri olan, eşsiz bir 'anlam kokusuna' sahip. Peki, bu milyonlarca kokulu lokmayı nerede saklayacağız ve aradığımızı saniyeler içinde nasıl bulacağız?
İşte bunu da gelecek yazılarda konuşacağız. O zamana kadar görüşmek üzere!
Yorumlar